
There are tools that help people work a little faster, and then there are tools that redraw the boundaries of what a small team can attempt. For Joe Don Levy, regional CTO at Endava, Codex belongs in the second category. “What Codex has really helped us do,” he says, “is have small teams of people deliver massive value in a very, very condensed timeframe.”
Most coverage of OpenAI’s Codex still frames it as a clever coding assistant: useful for boilerplate, maybe good for tests, handy if you do not want to write the same function twice. That framing is already out of date. Inside companies that have moved beyond the demo phase, Codex is becoming something more consequential: a workflow engine that can read, write, execute, explain and increasingly orchestrate work across the software lifecycle.
That distinction matters because it changes the real question. The interesting question is no longer whether Codex can produce code. It can. The more interesting question is what happens when a tool that began life as a coding assistant starts to behave more like a supervised junior engineer, then more like a desktop agent, and eventually more like infrastructure for knowledge work.
This is why the Endava story is worth paying attention to. Levy’s description of Codex is not that of a shiny developer toy. He talks about it as a force multiplier for small teams, a bridge between senior intent and junior execution, and a tool that now reaches beyond writing code into diagrams, explanation, and work across the lifecycle. Read closely, that is not really a story about coding. It is a story about leverage.
“What Codex has really helped us do is have small teams of people deliver massive value in a very, very condensed timeframe.”
This article argues that Codex is most valuable when teams stop treating it as autocomplete with marketing and start treating it as a workflow layer. It also makes a second claim: the next frontier is not just faster software delivery, but complex knowledge work across engineering, product, finance, operations and marketing. That sounds grandiose until you notice what Codex already does well: absorb context, execute repetitive steps, surface dependencies, and turn sprawling tasks into something one person can direct and review.
If that sounds exciting, it should. If it sounds risky, it should. The reality of Codex right now sits in that tension.
Codex, updated
The public imagination is still lagging behind the product. A lot of people are effectively responding to the 2021 version of Codex: text prompts in, code out, hopefully something useful happens. But OpenAI’s current positioning is much broader. In its own release materials, the company describes Codex as a cloud-based software engineering agent that can work on many tasks in parallel, run in isolated environments, answer questions about a codebase, write features, fix bugs and propose pull requests for review.
That matters because the modern Codex stack is not one thing. It includes the ChatGPT Codex surface, the CLI, IDE extensions and workflow guidance that explicitly tells teams to treat Codex like a teammate with explicit context and a clear definition of done. This is not “AI that completes a line of code”. This is “AI that can participate in a multi-step engineering process”, complete with tests, logs, branch workflows and review points.
OpenAI is quite open about what makes this work: Codex agents perform best when they are given reliable testing setups, configured environments, and clear repository documentation such as AGENTS.md files that explain how to navigate the codebase and run the right checks. In other words, Codex rewards teams that already know how to make work legible. That is an important clue. The productivity gains are real, but they do not appear by magic; they appear when process, documentation and model capability reinforce one another.
How Codex changes developer workflows
Most developer time is not spent inventing brilliant greenfield solutions. It disappears into reading, tracing, checking, rewriting, running tests, updating documentation, and trying not to break things. OpenAI’s own workflow documentation reflects this reality. The examples are not glamorous. They are about explaining a codebase, fixing a bug with a clear repro recipe, writing tests against an existing function, reviewing a pull request, or delegating a carefully scoped refactor to a cloud agent.
That is why Codex is more important than it first appears. It changes the cost of the boring middle. A senior engineer can now write an intent-rich brief, ask Codex to inspect the relevant files, propose the change plan, draft the implementation, run the relevant tests and summarise what changed. The engineer still reviews and decides. But the work between “I know what should happen” and “here is a patch worth reviewing” gets compressed.
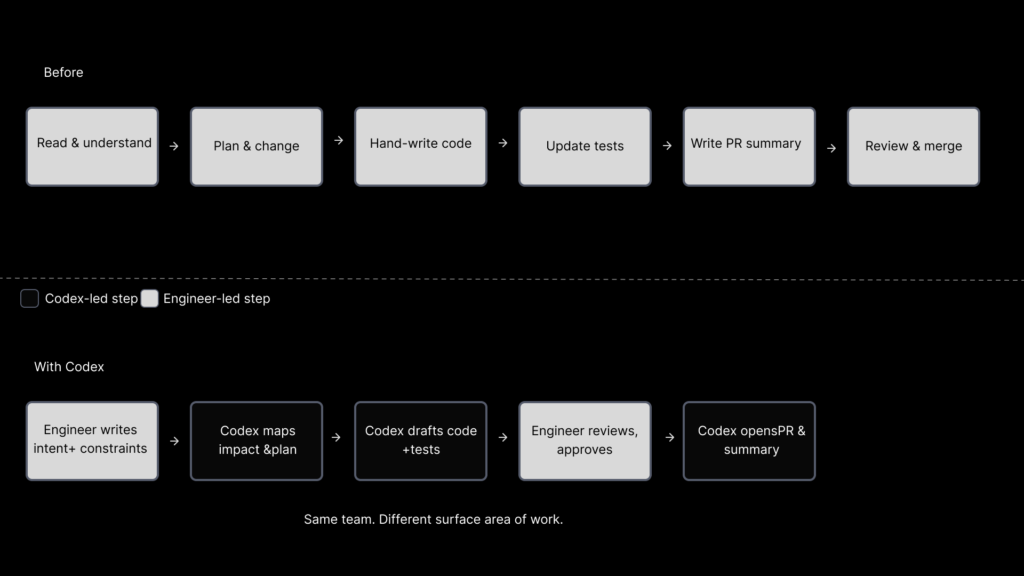
At Endava, Levy describes this as something that unlocks both ends of the team structure. “Senior architects like myself coming from complex environments,” he says, “are able to articulate what we want and Codex is able to really make that an accessible piece of information for the more junior people on the team.” At the same time, juniors can “create like senior and mature level kind of outputs”.
That is one of the clearest descriptions yet of how agentic coding changes teams. It is not simply that Codex writes code more quickly than a person. It is that Codex can act as a translation layer between senior intent and junior execution. Senior engineers spend more time shaping the problem, setting constraints and defining quality. Junior engineers spend less time staring at a blank file and more time reviewing, learning and refining. Codex fills some of the gap in between.
“We’re able to articulate what we want and Codex is able to really make that an accessible piece of information for the more junior people on the team.”
This is a subtle but profound shift. Traditional conversations about AI coding tools often collapse into labour anxiety: does this replace juniors, does it deskill engineers, does it make everybody average? The Endava framing points in a different direction. Codex can raise the floor for less experienced developers while freeing experienced ones to operate more at the level of architecture, review and judgement. That does not eliminate the need for talent. It changes where talent creates value.
The rise of the supervised agent
The easiest way to misunderstand Codex is to assume it is mostly useful when it gets to write code. The more interesting use case is when it gets to do the surrounding work.
OpenAI’s own examples show this clearly. Codex is positioned as useful for onboarding to a codebase, understanding protocols and data models, reproducing bugs, generating regression tests, reviewing working trees, drafting documentation and running long refactors in the cloud while the developer keeps moving elsewhere. None of that is glamorous, but it is exactly the sort of work that eats up engineering attention.
This is where Levy’s other comment becomes important. “As Codex has matured,” he says, “we see it more than just a coding tool. We really see it as more of a general kind of desktop agent to use across our whole life cycle rather than just specifically targeting the coding capability.”
That phrase, “desktop agent”, should set off alarms and possibilities in equal measure. It suggests a shift away from the old interaction model where a human prompts and the model responds in a narrow text box. Instead, the model begins to inhabit workflows: reading local context, inspecting files, generating explanations, producing diagrams, opening branches, writing tests, creating pull requests and surfacing logs as evidence.
Once that happens, the work starts to look less like pairing with a chatbot and more like supervising a collaborator. OpenAI even hints at this in its documentation and release notes, repeatedly describing Codex as best used with explicit definitions of done, reliable verification steps, and isolated environments. That is not how you describe a toy. That is how you describe a new operational layer.
Tiny teams, huge surface area
One of the most compelling claims in the Endava material is not about speed in the abstract. It is about scope. Levy’s point is not simply that Codex saves time on familiar work. It is that small teams can now attempt work that used to feel out of proportion to their size.
This is where the story gets strategically interesting. In software organisations, headcount has long been a proxy for surface area. If you wanted to support more services, try more experiments, tackle more refactors, or build internal tools alongside client work, the usual answer was some version of: hire more people, wait longer, or lower your ambition.
Codex starts to change that equation in three ways. First, it reduces the activation energy for starting things. A developer does not have to hold the entire implementation in their head before they begin. They can write a tighter spec, ask Codex to propose an approach, and refine from there. Second, it makes context recovery less punishing. Engineers constantly lose time to rediscovering how systems work, especially in messy enterprise environments. Codex can help explain flows, list files involved in a process, call out gotchas, and summarise request lifecycles in ways that are easier to validate than reading raw code from scratch. Third, it absorbs a meaningful chunk of the repetitive implementation burden. Refactoring, renaming, wiring components, fixing integration failures, writing tests, updating docs: OpenAI’s own early testers highlight these as areas where Codex saves attention and keeps engineers in flow.
None of this means one engineer suddenly becomes ten engineers. It means small teams can punch above their weight more often, on more kinds of tasks, with less overhead in between. That is still a major change.
“The shift has gone from us producing a lot of the code ourselves to us now overseeing the work that Codex can produce.”
The next frontier: complex knowledge work
If the story ended with engineering, it would still be important. But the more radical possibility is that software engineering is only the first organisational function to feel this shift clearly.
Once a model can ingest large amounts of context, follow structured instructions, execute repeatable actions, cite what it did and return outputs in useful formats, the boundary between coding work and knowledge work starts to blur. In fact, some of OpenAI’s own framing already points beyond engineering. Codex can answer questions about systems, generate documentation, produce summaries and work asynchronously in ways that resemble a remote collaborator more than an autocomplete feature.
This matters because the same ingredients that make Codex useful in software engineering exist elsewhere in the organisation. In product, teams juggle specs, support logs, ticket backlogs, research notes and dependency maps. Operations deals with dashboards, exports, process documents and recurring exception handling. Finance runs on spreadsheets, reconciliations, scenario models and reporting cycles. Meanwhile, marketing works across campaign data, CRM exports, content systems and review loops. None of these domains are “just coding”, but all of them involve large volumes of information, repetitive interpretation, and mechanical steps that sit between intent and decision.
That is why the idea of Codex as a “general desktop agent” matters. The frontier is not simply getting better at writing functions. It is giving teams a supervised agent that can help process sprawling information, transform it into structured outputs, and reduce the time wasted on the connective tissue of work.
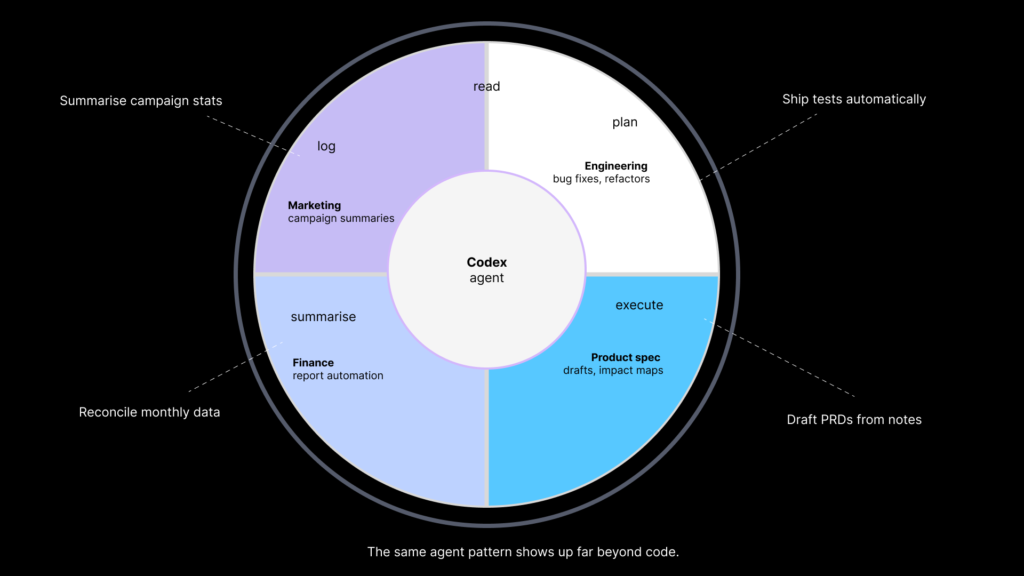
The language matters here. This is not a claim that Codex is about to replace product managers, finance teams or marketers. It is a claim that many of the tasks they currently do manually are structurally similar to the engineering tasks Codex already helps with: ingest context, identify relevant files or inputs, apply constraints, generate a first pass, validate, then hand back to a human reviewer.
Seen this way, Codex looks less like a coding breakthrough and more like a prototype for a wider class of work agents.
Why this matters now
There is a timing argument here that is easy to miss. The reason this topic matters now is not just that the model got better. It is that the form factor changed.
A lot of the early enthusiasm around generative AI in engineering was trapped in chat windows. People copied and pasted code into prompts, accepted or rejected snippets, and debated whether the output was good enough. That was useful, but limited. Once Codex moved into cloud sandboxes, CLI workflows, IDE extensions and review loops with verifiable logs and test outputs, it crossed a threshold.
At that point, the conversation changes from “can it generate code?” to “where in our workflow should an agent sit?” That is a much bigger organisational question. It touches team design, review culture, testing discipline, security posture and internal documentation. It also explains why adoption feels lumpy. Teams with weak process often get less value than teams with strong process, because Codex amplifies legibility. If your work is already structured, it has something to latch onto. If your work is chaotic, it can only automate the chaos faster.
That is why the winners here may not be the teams with the most model enthusiasm, but the teams that are best at making work explicit.
Hidden productivity secrets from the inside
If you strip away the hype, the real “secrets” behind Codex productivity are not secret at all. They are workflow disciplines.
The first is that Codex works best when the task is well-scoped. OpenAI says this directly. Its workflow guidance repeatedly emphasises explicit context, clear steps, constraints and verification. This sounds almost boring until you realise how many teams try to use AI tools as mind-reading machines. Vague prompt in, disappointed shrug out. Codex is powerful, but it is not telepathic. The better the brief, the better the result.
The second is that verification is not optional. OpenAI keeps stressing terminal logs, test outputs and review traces as evidence of what Codex did. That is not just a safety feature. It is a trust feature. Teams adopt agents more readily when they can inspect not only the output but the path taken to get there.
The third is that async work is the real unlock. Codex becomes especially valuable when it can run on longer tasks in parallel while humans keep moving. OpenAI’s cloud delegation workflows make this explicit: plan locally, delegate implementation to the cloud, review the diff later, repeat. This matters because it turns the model from something you pair with moment to moment into something that can absorb background work without monopolising your attention.
The fourth is that the biggest gains are often indirect. Codex does not just save time on typing. It saves cognitive load: fewer context switches, faster onboarding, less friction when coming back to an old codebase, less time wasted writing first-pass documentation or scaffolding tests. These are not always the things teams measure first, but they are often what make the week feel different.
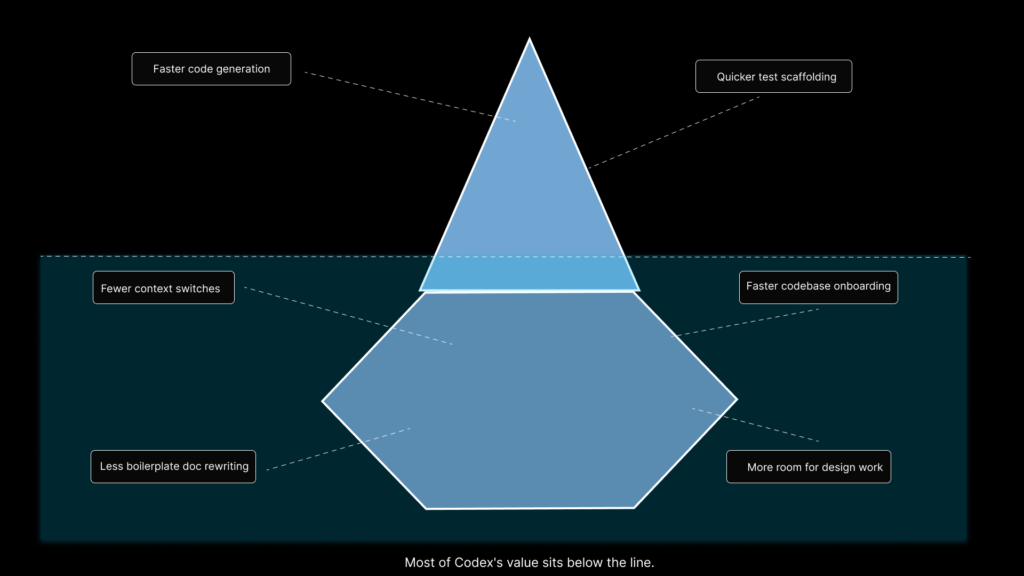
How teams can solve Codex’s biggest pain points
None of this means the complaints about Codex are wrong. Some are narrow and version-specific, but others — especially around security, workflow friction and uneven output quality — are serious. The useful question is not whether these problems exist, but how teams can design around them before they become expensive.
Fix code quality with process, not hope
If Codex is generating brittle or over-engineered code, the answer is not simply to give up on it. It is to put it behind stronger guardrails. OpenAI’s own product materials make clear that Codex performs best with clear instructions, configured environments, and reliable testing setups. Teams that get the most value out of the tool tend to pin known-good model versions, use reusable brief templates, and insist that Codex-generated changes sit behind tests before they touch critical modules.
The practical principle is simple: Codex should not be the first line of trust. Tests, review and explicit constraints should be. That changes the role of the tool from “unpredictable shortcut” to “supervised contributor”. It also means treating model upgrades with the same seriousness you would apply to runtime upgrades or framework migrations. If one version regresses, you stage it, test it, and only then roll it out.
Treat token burn like an operational metric
A surprising amount of Codex frustration is really about cost visibility rather than raw model capability. OpenAI itself says that today’s generous access will eventually give way to rate-limited access and flexible pricing, while the API already prices Codex models by input and output tokens with prompt-caching discounts. If teams do not instrument usage, token burn feels like a scam. If they do instrument it, it becomes a metric.
That means tracking spend by workflow, by repository and by model choice. It means using lighter models for planning or summaries and reserving the heaviest variants for tasks where the extra quality genuinely matters. It also means teaching teams which habits waste context: repeatedly pasting huge logs, re-describing the same repository on every run, or using expensive models for work that does not need them. Once token usage becomes visible, teams can govern it instead of just resenting it.
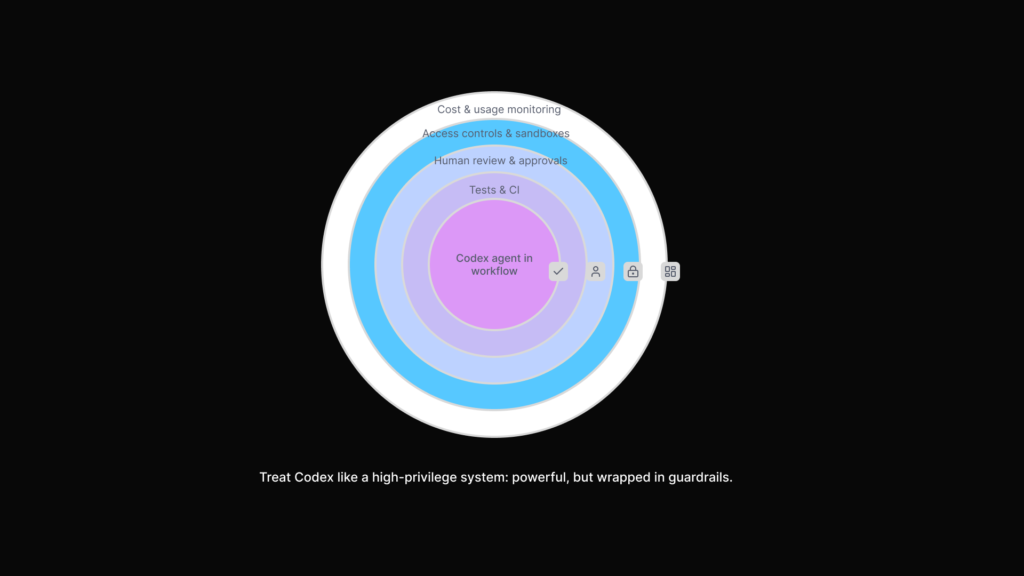
Handle security like any other privileged system
Security concerns deserve more weight than generic “AI panic” because some of the risks are obvious and structural. OpenAI itself foregrounds isolated environments, disabled internet by default, and the importance of review before execution or integration. That is already a clue that Codex should be treated like a high-privilege system, not a casual assistant.
In practice, mature teams sandbox Codex’s reach. They give it least-privilege credentials, restrict write permissions to safe environments, keep it away from production secrets, and require human approval for sensitive actions. They also log what it did, so behaviour can be audited later. The right posture is neither blind trust nor blanket fear. It is controlled exposure.
Solve integration pain with standard workflows
When developers complain that the CLI, extension or planning flow is flaky, the underlying problem is often fragmentation. OpenAI’s workflow pages are useful partly because they encourage teams to think in repeatable patterns: explain a codebase, fix a bug with a repro recipe, write a test, review a working tree, delegate a refactor. In other words, there are golden workflows.
Teams can reduce integration pain by formalising a small set of those workflows inside the organisation. Wrap Codex behind an internal layer if needed. Standardise prompts, parameters, logging and verification. Turn the “best way we use Codex here” into a visible operating model, not folklore. That lowers cognitive load and makes future changes to models or tooling easier to absorb.
Lower the UX friction and raise the honesty
Some Codex backlash is less about raw capability than about ergonomics and expectation mismatch. If the tool interrupts badly, hides cost, or is marketed as magic while still behaving like a moody teammate, trust erodes fast. OpenAI’s own documentation is actually helpful here because it is fairly plain about where Codex is still early: remote delegation takes longer than live editing, course correction mid-task is limited, and some capabilities are still missing.
This is where enablement matters. Teams need calm defaults, realistic onboarding, explicit guidance on what Codex should and should not be used for, and internal examples that show both success and failure modes. Good AI adoption is not just a tooling problem. It is a product management problem inside the organisation.
Codex is not most useful when people believe the hype. It is most useful when teams know exactly where it is strong, where it is brittle, and how to build guardrails around both.
This is where AI enablement becomes strategic
The organisations that get past the first wave of Codex frustration are usually not the ones with the loudest pilots. They are the ones that treat adoption as a systems problem: assess readiness, choose one painful workflow, define a clear before-state, add guardrails, instrument costs and quality, then improve from there.
This is also where AI enablement stops being a vague innovation label and becomes a serious operating discipline. The valuable work is not sprinkling prompts on a messy process. It is redesigning the workflow so that the model, the humans and the governance reinforce each other.
That matters for consulting too. The teams that need help here rarely need another sermon about disruption. They need someone who can map a workflow, identify the repetitive steps, decide where an agent belongs, define guardrails, and prove that the result is faster, safer or both. In that sense, Codex is not just a developer tool story. It is a consulting wedge into a broader organisational problem: how to turn AI capability into repeatable, measurable operating leverage.
Codex is not the hero; your workflow is
It is tempting to write about Codex as if it is the hero of the story: the AI that writes the code, saves the week and revolutionises software delivery. That version is simple, and wrong.
Codex is closer to an operating system for work than a coding assistant. In practice, more of the mechanical steps recede into the background while small teams gain the leverage of much larger ones. Senior engineers can spend more of their time where judgement actually matters, and junior developers can produce work that would once have taken much longer to reach.
But Codex does not tell you what to build. It does not define quality for you. It does not fix brittle ownership, bad incentives or the lack of a coherent operating model. Those are still human problems.
The companies that get the most from Codex over the next few years will not necessarily be the ones that adopt first, or talk loudest. They will be the ones that redesign work most intelligently around a supervised, capable agent. In other words, Codex does not revolutionise anything on its own. What it offers is leverage. Whether that leverage turns into faster delivery, better knowledge work and more ambitious teams depends on what kind of systems people build around it.
Footnotes
YouTube, “What Codex Unlocks for Endava”, published 10 May 2026.
OpenAI, “Introducing Codex”, 16 May 2025.
OpenAI Developers, “Workflows – Codex”, accessed May 2026.
Reddit, “Codex Usage Messed Up - Shame on OpenAI”, accessed May 2026.
GitHub, “Burning tokens very fast · Issue #14593 · openai/codex”, accessed May 2026.
TechRadar, “Security experts discover critical flaw in OpenAI's Codex which could compromise enterprise organisations”, accessed May 2026.