Last week, OpenAI and JetBrains announced that Codex—the “most advanced agentic coding model”—now works natively in IntelliJ IDEA, PyCharm, WebStorm, and Rider. The nine-minute demo looked slick: an AI agent debugged an iOS build error and implemented Spanish localisation across a Kotlin multiplatform app, all while the developer “stayed in flow”.
Senior engineering leaders shared the video in Slack channels with fire emojis. Several asked their teams to trial it immediately. Somewhere, a procurement spreadsheet quietly woke up.
Here’s what nobody’s saying out loud: that demo bears almost no resemblance to what happens when you actually deploy AI coding agents at scale. And the gap between the two is costing companies real money while burning out their best engineers.
This isn’t anti-AI hand-wringing. MIT Technology Review just named generative coding a 2026 breakthrough technology, and they’re right—this shift is permanent.¹ Andrej Karpathy’s “vibe coding” isn’t hype; it’s already how millions of developers work.²
“The question is no longer whether AI will write code. It’s whether your organisation can survive the way it currently does it.”
There’s a massive difference between what works for Karpathy building weekend projects and what enterprises need to ship systems that don’t leak customer data or fall over at 2am.
The Codex demo reveals something more interesting than whether this particular tool is good or bad. It exposes the systemic mismatch between how vendors sell AI coding agents and how engineering actually works. As I explored in my analysis of Claude’s marketing restraint,³ the AI industry is still learning how to position these tools honestly⁴—and the disconnect creates real problems for teams trying to extract actual value.
The Demo Playbook: Why Everything Looks Magical
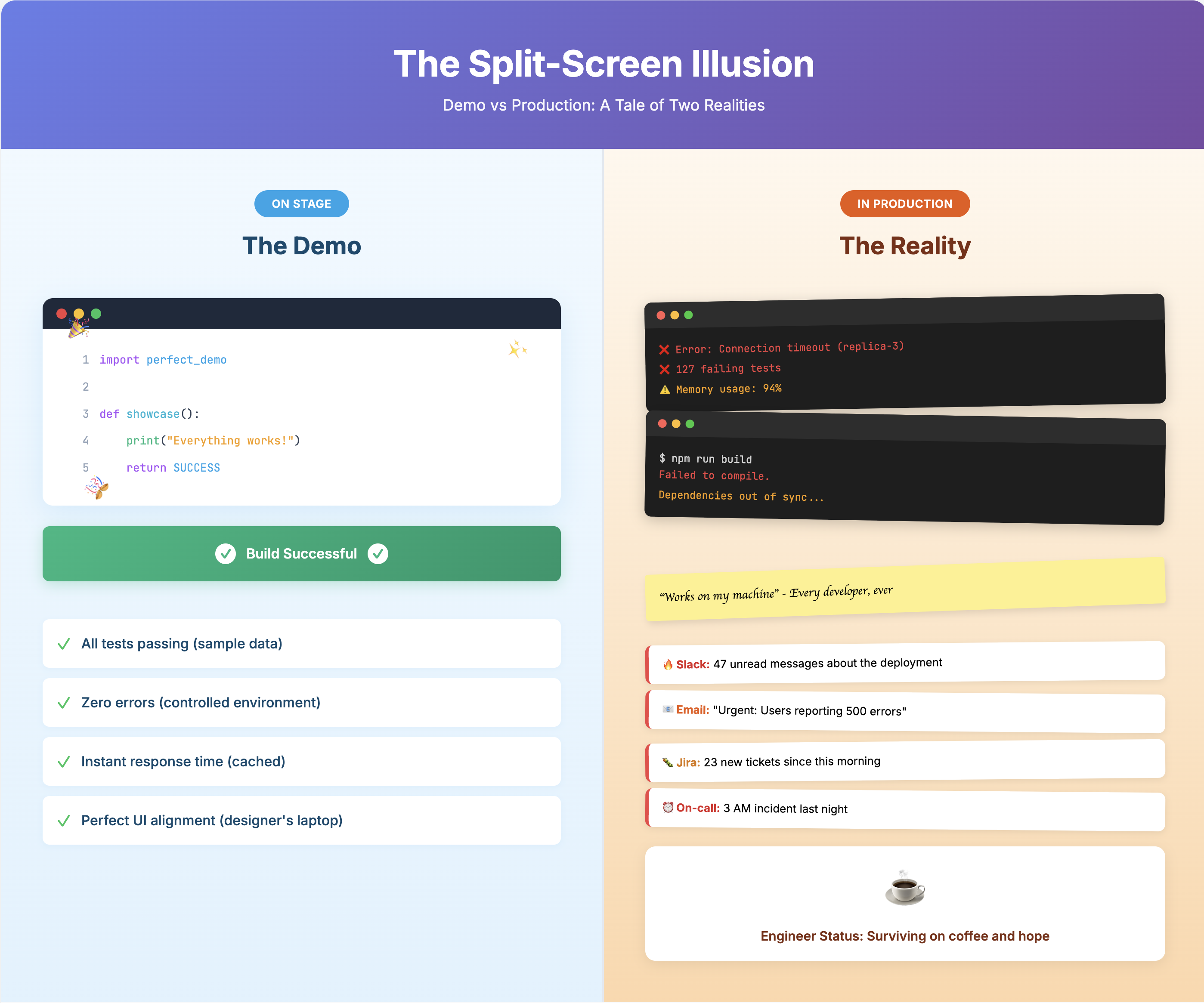
Software demos follow a well-worn formula. You showcase tasks optimised for success, edit out false starts, and carefully select environments where your tool shines. The Codex demonstration⁵ is textbook execution: two carefully chosen tasks on a polished reference codebase.
Task one: Fix an iOS build error from a stack trace. The presenter copies red terminal text, pastes it into Codex with “help me solving that”, and two minutes later the build succeeds.
Task two: Implement Spanish localisation across Android, iOS, web, and desktop. Codex identifies the localisation pattern, generates translation strings, runs Gradle to verify compilation, and produces a working Spanish-language app in roughly three minutes.
Both tasks showcase genuine AI strengths. Build errors from stack traces are pattern-matching exercises—exactly what large language models trained on millions of Stack Overflow threads and GitHub issues excel at. Localisation strings are boilerplate generation at scale: identify a structure once, replicate it everywhere. These are valuable use cases. They’re also intellectually trivial in ways the demo doesn’t acknowledge.
“Demos are the holiday photos of software: beautifully lit, ruthlessly cropped, and silently ignoring the disasters that happened just off-frame.”
What’s missing? Everything that makes enterprise software development hard:
- Ambiguous requirements that change mid-sprint
- Legacy codebases with ten years of technical debt
- Proprietary frameworks absent from training data
- Security vulnerabilities requiring attack-vector reasoning
- Performance bottlenecks demanding algorithmic trade-offs
- Merge conflicts when three developers modify overlapping code
- Production incidents with incomplete information and time pressure
The demo uses the KotlinConf reference app—a showcase project built for clean architecture. Your team’s actual codebase has six different architectural paradigms, inconsistent naming conventions, and that one module nobody understands because the original author left in 2019. AI coding agents trained on public repositories struggle with “anything too far outside that norm”,⁶ which describes most enterprise code.
This isn’t dishonesty; it’s marketing.

But when engineering leaders extrapolate from five-step demo workflows to their fifty-step production reality, they’re setting up for expensive disappointment.
The Maths That Demos Avoid: Compounding Errors
Here’s the brutal reality nobody mentions in polished product launches: even at 95% reliability per step, a twenty-step workflow succeeds only 36% of the time.⁷
GPT-5.2-Codex achieves 74.5% on SWE-Bench Verified⁸—the gold standard for AI coding evaluation. That’s genuine progress. It’s also one in four tasks failing on carefully curated GitHub issues that have been pre-validated as solvable. In production, where requirements are ambiguous and success criteria are fuzzy, failure rates climb higher.
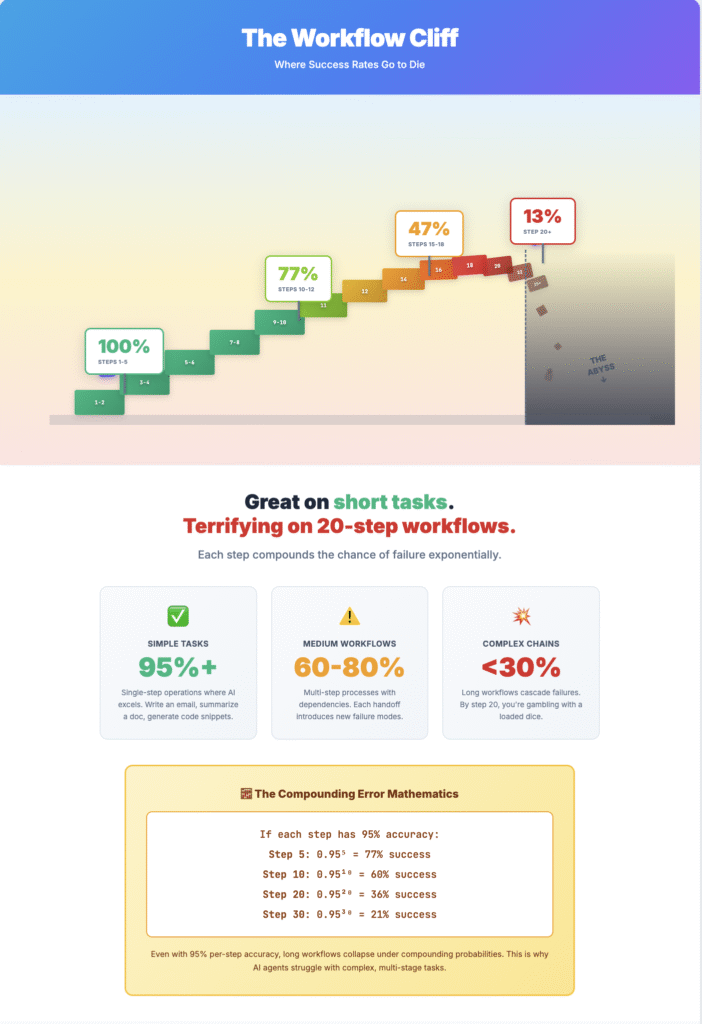
The Codex demo features short-horizon tasks: maybe ten reasoning steps for the build error, fifteen for localisation. Real enterprise work—refactoring authentication systems, migrating database schemas, implementing complex business logic—routinely hits fifty or more steps. At 95% per-step reliability, that’s a 7.7% success rate. At 98%? Still only 36%.
“At 95% reliability per step, your AI agent is not a superhero. It’s a very enthusiastic intern with a 64% chance of breaking something on a long task.”
This exponential degradation explains why so many organisations pilot AI coding tools with enthusiasm and then quietly shelve them six months later. The pilot uses demo-friendly tasks and succeeds. Production deployment encounters real complexity and collapses.
The Productivity Inversion Nobody Saw Coming
The promise sounds irresistible: AI writes code faster than humans, so developers must become more productive.
The data says otherwise.
A rigorous study using randomised control trials found developers using AI assistance completed full-pipeline tasks 19% slower than those coding manually—despite believing they were faster.⁹ LeadDev’s 2025 engineering survey found 60% of engineers report no meaningful productivity gains from AI tools.¹⁰
How is that possible? Because the work fundamentally shifted.
Before AI coding agents, developers spent roughly 65% of their time writing new code. With AI agents, that plummets to 25%.¹¹ The difference gets consumed by:
- Debugging AI output: 35% of time
- Re-providing context (because agents lack persistent memory): 15%
- Manual unblocking when agents fail: 12%
- Increased code review scrutiny (because 15–25% of AI-generated code contains security vulnerabilities)¹²
“We didn’t automate coding; we automated a new category of bug, and then paid senior engineers to chase it around the codebase.”
You’ve inverted developer cognitive effort. Instead of amplifying high-value creative work, you’re asking senior engineers to babysit systems that hallucinate solutions, skip safety checks, or fabricate explanations. One architect at a Fortune 500 company put it perfectly: “We went from building to butler service for an agent that doesn’t understand our business.”
This isn’t universal. Some teams see real gains, particularly on the specific use cases research validates: stack trace analysis, test generation, documentation writing, learning unfamiliar codebases.¹³ But those narrow wins don’t justify blanket “AI will 10× productivity” claims that drive purchasing decisions.
What Actually Works: A Framework That Isn’t Theatre
The right question isn’t “Should we use AI coding tools?” It’s “How do we extract value without the overhead eating the gains?”
Organisations getting this right—and yes, they exist—follow patterns that demos never show. These lessons echo what I’ve seen across enterprise AI implementations: success requires honest assessment of capabilities, clear governance frameworks, and measurement that reflects reality rather than vendor promises.

Start Narrow, Measure Honestly
Don’t roll out AI coding agents across your entire engineering organisation. Pilot on well-defined workflows with clear success metrics: test generation for a legacy module, documentation updates, simple refactoring tasks.¹⁴
Measure what actually matters for business value, not vanity metrics. Lines of code written and task completion time are useless. Track full cycle time (idea to production), lead time for changes (commit to deploy), defect escape rate, and developer satisfaction.¹⁵ If cycle time improves less than 10%, the gains don’t justify total cost of ownership and change management overhead.
Run controlled experiments lasting at least two sprints. Compare AI-enabled teams against control groups. Require statistical significance before declaring success.¹⁶ One VP of engineering instituted a rule: “If you can’t show me the p-value, we’re not buying it.” Harsh, but refreshingly clear.
Governance Before Scale
The three-tier access model Codex demonstrates—read-only, agent mode with constant approvals, or full autonomy—creates a false choice.¹⁷ Production systems need fine-grained permissions, comprehensive audit logs, rollback mechanisms for state-changing operations, and approval workflows for high-risk actions.
Enterprise governance frameworks that work require:¹⁸
- Human code review mandatory for all AI-generated changes, not optional
- Automated security scanning specifically targeting patterns AI tools commonly miss (SQL injection, XSS, authentication bypasses)
- Audit trails tracking which code was AI-generated for regulatory compliance
- Sandboxed testing environments where AI-suggested code runs before touching anything production-adjacent
- Clear escalation paths when agents fail or produce incorrect output
This isn’t bureaucracy; it’s how you avoid the scenario where an autonomous agent drops a production database because it misunderstood context.
Training Is Not Optional
Developers need structured education on when to use AI, how to validate output, and how to integrate it into existing workflows.¹⁹ Organisations that skip training see 60% lower productivity gains compared to those with formal programmes.
High-performing teams create internal prompt libraries: version-controlled collections of high-quality, reusable prompts for common tasks (generating unit tests, refactoring for readability, security flaw identification). This scales best practices and accelerates adoption without everyone reinventing the wheel.
“If your AI ‘strategy’ is just: buy seats, send a link, hope for magic—you don’t have a strategy. You have a SaaS subscription.”
The most effective training acknowledges AI limitations explicitly. One company’s internal guide opens with: “AI coding tools are junior developers who never get tired, never get better at your business domain, and never remember what you discussed yesterday. Manage them accordingly.”
Integrate, Don’t Disrupt
The highest-ROI applications, in order of measured time savings: stack trace analysis, refactoring existing code, mid-loop code generation, test case generation, and learning new techniques. Prioritise these. Avoid using AI for security-critical authentication logic, complex architectural decisions requiring trade-off analysis, or domain-specific business logic absent from public training data.
Treat AI tools as force multipliers that augment capabilities, not replacements for human expertise.²⁰ The most successful implementations position developers as “leads” for teams of AI agents, measured on combined team performance—similar to how DevOps engineers manage Jenkins pipelines, not write every build script manually.
The Questions Your Demo Skips
When evaluating any AI coding tool—not just Codex—probe beyond polished presentations:
On capability limits: What’s your measured error rate on enterprise codebases with proprietary frameworks? How does performance degrade with technical debt and inconsistent architecture? What percentage of tasks require human intervention to complete?
On workflow integration: How do you handle secrets, credentials, and environment-specific configurations? What happens when multiple developers use agents simultaneously on overlapping code? How do outputs integrate with existing CI/CD, security scanning, and approval gates?
On security and compliance: What percentage of generated code contains vulnerabilities? How do you support SOC 2, HIPAA, GDPR, and industry-specific requirements? Can you provide audit trails for regulatory reviews?
On ROI: What full-cycle-time improvements have customers measured in production—not in pilots? Can you provide references willing to discuss defect rates and developer satisfaction twelve months post-deployment?
If a vendor can’t answer these, you’re buying demo theatre, not production capability.
Why This Matters Beyond One Product
The Codex–JetBrains integration is one data point in a tectonic shift. Over 36 million developers joined GitHub in 2025; Copilot usage now dominates new-user workflows. The AI code generation market hit roughly $5.8 billion in 2025 with double-digit CAGR forecast through 2035. This isn’t a fad; it’s infrastructure.
But infrastructure succeeds or fails based on how it integrates with human workflows, not on demo performance. History is littered with technologies that looked revolutionary in controlled environments and collapsed in production: voice interfaces that couldn’t handle accents, computer vision that failed on edge cases, automation that introduced more errors than it solved.²¹
The path forward isn’t to reject AI coding tools; it’s to deploy them where they deliver actual value, measure honestly, and refuse to accept marketing claims as engineering truth. As I’ve explored in my analyses of AI marketing evolution—from Anthropic’s restraint strategy to OpenAI’s positioning—the companies succeeding are those honest about limitations whilst maximising genuine strengths.
“AI isn’t here to replace developers. It’s here to expose every weak process you’ve been getting away with for a decade.”
When a demo shows an agent autonomously implementing features while developers “stay in flow”, ask what happens at step 23 when the agent confidently writes code that passes tests but violates an undocumented business rule that causes financial loss.
So What Do You Actually Do on Monday?
If you’re evaluating AI coding tools or already deploying them, here’s how to turn demo energy into something your future self won’t regret.
This week: Establish baseline metrics for cycle time, lead time, defect rates, and developer satisfaction. If you’ve never measured these, the “lift” from AI is guesswork. (Your first AI initiative should probably be better analytics, not more agents.)
This month: Define your high-value use cases based on research, not vendor promises.²² Pilot on those specific workflows with clear go/no-go criteria. One or two use cases. Not twelve. Not “everything”.
This quarter: Build your governance framework—security scanning, audit logs, approval workflows—before scaling beyond early adopters. Invest in training that teaches developers when not to use AI, not just how to prompt it.
“The real competitive edge won’t be who adopts AI first. It will be who survives their own adoption curve.”
AI coding agents will get better. GPT-5.2-Codex outperforms GPT-4 significantly; GPT-6 will outperform GPT-5. But even at 99% per-step reliability, fifty-step workflows still fail 39% of the time. The fundamental challenge isn’t model capability—it’s matching tool strengths to appropriate use cases whilst building systems that gracefully handle failures.
The companies winning aren’t those deploying AI fastest; they’re those deploying it most thoughtfully. They measure impact,²³ acknowledge limitations, iterate based on evidence, and refuse to treat demos as documentation of production capability.
Your next demo will look perfect. Your production deployment doesn’t have to be a mess—if you stop pretending the two are the same thing.
Sources & Further Reading
External Research & Analysis
<a name=”footnote1″>¹</a> MIT Technology Review (2026). “10 Breakthrough Technologies 2026“. Technology Review.
<a name=”footnote2″>²</a> AI Certs (2026). “MIT Declares AI Coding Tools 2026 Breakthrough“. AI Certification News.
<a name=”footnote5″>⁵</a> JetBrains Blog (2026). “Codex Is Now Integrated Into JetBrains IDEs“. JetBrains AI.
<a name=”footnote6″>⁶</a> Zencoder (2024). “Limitations of AI Coding Assistants: What You Need to Know“. Zencoder AI Blog.
<a name=”footnote7″>⁷</a> Rossi, L. (2026). “Making AI agents work in the real world“. Refactoring.
<a name=”footnote8″>⁸</a> AI Rank (2025). “SWE-Bench Verified Benchmark“. AI Rank Benchmarks.
<a name=”footnote9″>⁹</a> Chen, L. (2025). “AI Tools for Developer Productivity: Hype vs. Reality in 2025“. Dev.to.
<a name=”footnote10″>¹⁰</a> Mohan, K. (2025). “Everyone’s shipping an AI agent these days“. LinkedIn Post.
<a name=”footnote11″>¹¹</a> Development Corporate (2025). “Why AI Coding Agents Are Destroying Enterprise Productivity“. Development Corporate.
<a name=”footnote12″>¹²</a> Maxim AI (2026). “AI Agent Security Risks: What Every Developer Needs to Know“. Mint MCP Blog.
<a name=”footnote13″>¹³</a> DX (2025). “AI code generation: Best practices for enterprise adoption“. DX Research.
<a name=”footnote14″>¹⁴</a> Augment Code (2025). “AI Agent Workflow Implementation Guide“. Augment Guides.
<a name=”footnote15″>¹⁵</a> DevDynamics (2024). “Cycle Time vs. Lead Time in Software Development“. DevDynamics Blog.
<a name=”footnote16″>¹⁶</a> DX (2025). “How to measure AI’s impact on developer productivity“. DX Research.
<a name=”footnote17″>¹⁷</a> OpenAI Community (2025). “Challenges With Codex – Comparison with GitHub Copilot and Cursor“. OpenAI Developer Forum.
<a name=”footnote18″>¹⁸</a> Maxim AI (2025). “The Ultimate Checklist for Rapidly Deploying AI Agents in Production“. Maxim AI Articles.
<a name=”footnote19″>¹⁹</a> Joseph, A. (2025). “AI Code Assistants – Comprehensive Guide for Enterprise Adoption“. Ajith P. Blog.
<a name=”footnote20″>²⁰</a> Terralogic (2025). “How AI Agents Are Revolutionizing Software Development Workflows“. Terralogic Blog.
<a name=”footnote21″>²¹</a> The Sales Hunter (2025). “10 Demo Mistakes that Are Killing Your Sales“. Sales Best Practices.
<a name=”footnote22″>²²</a> Swarmia (2025). “The productivity impact of AI coding tools: Making it work in practice“. Swarmia Engineering Blog.
<a name=”footnote23″>²³</a> Software Seni (2025). “Measuring ROI on AI Coding Tools Using Metrics That Actually Matter“. Software Seni Blog.
Related Articles on Suchetana Bauri’s Blog
<a name=”footnote3″>³</a> Bauri, S. (2025). “Selling AI Without Showing Product: Claude’s Thinking Partner Paradox“. SB Blog.
<a name=”footnote4″>⁴</a> Bauri, S. (2025). “Claude Sonnet 4.5 Marketing Analysis: When AI Companies Learn Restraint“. SB Blog.
For frameworks to measure AI coding tool impact correctly, see DX Research’s comprehensive measurement guide. For enterprise adoption playbooks, review this strategic implementation framework covering evaluation, governance, and scaling.