Rather intriguingly, tucked away in the arcane realm of Google’s research laboratories, a rather clever bit of algorithmic engineering has been quietly brewing. MUVERA—Multi-Vector Retrieval Algorithm—represents what one might call a rather elegant solution to a problem that has been vexing computer scientists for quite some time: how does one make multi-vector search as zippy as single-vector search without losing that precious accuracy?

Multiple data streams are compressed and channelled into a single, optimised output—an abstract representation of MUVERA’s approach to transforming complex multi-vector search into efficient single-vector retrieval.
The Conundrum of Scale
The chap who first encounters the notion of multi-vector retrieval might be forgiven for thinking it sounds rather like computational overkill. After all, isn’t one vector per document perfectly adequate? Well, not quite. The boffins at Google discovered that representing each document as a collection of vectors—rather like having multiple perspectives on the same subject—yields dramatically better search results1. ColBERT, the pioneering model in this space, demonstrated that by creating one vector per token, search systems could capture far more nuanced semantic relationships2.

The rub, however, lies in the computational cost. Multi-vector models require what’s called Chamfer similarity—a rather sophisticated mathematical operation that compares sets of vectors3. It’s rather like comparing two orchestras by listening to how well each musician pairs with their counterpart in the other ensemble. Computationally speaking, this is hideously expensive when you’re dealing with billions of documents.
Enter MUVERA: The Algorithmic Sleight of Hand
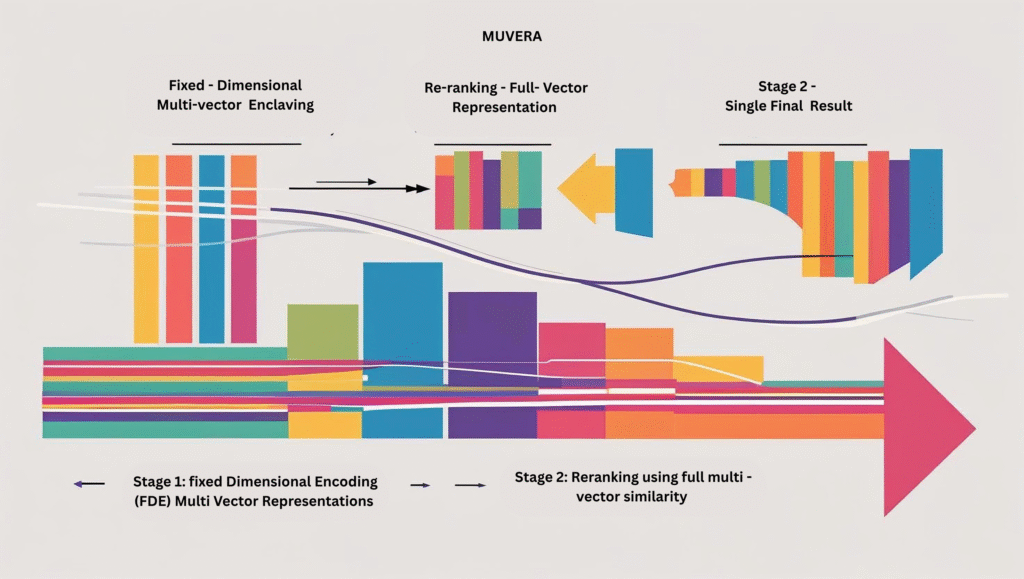
A conceptual illustration of MUVERA’s architecture: Stage 1 compresses multi-vector representations using Fixed Dimensional Encoding (FDE), while Stage 2 re-ranks candidates using full multi-vector similarity—delivering both efficiency and semantic depth.
Google’s researchers—Rajesh Jayaram and Laxman Dhulipala—have concocted what can only be described as a rather brilliant bit of mathematical legerdemain4.
MUVERA transforms the complex multi-vector similarity problem into a single-vector Maximum Inner Product Search (MIPS) problem. It’s rather like taking a complicated orchestral score and reducing it to a single melodic line that captures the essence of the entire symphony.
The key innovation lies in what they call Fixed Dimensional Encodings (FDEs). These are compact representations that preserve the essential similarity information from the original multi-vector sets45. Think of it as creating a fingerprint that captures the essence of an entire hand.
By reducing multi-vector search to single-vector MIPS, MUVERA leverages existing optimised search techniques and achieves state-of-the-art performance with significantly improved efficiency.
The Theoretical Underpinnings
What makes MUVERA particularly fascinating is its theoretical foundations. The algorithm draws upon probabilistic tree embeddings—a rather esoteric branch of computational geometry that deals with mapping complex structures into simpler spaces67. The beauty of this approach is that it provides provable guarantees about the quality of the approximation4.
The researchers have demonstrated that FDEs can achieve what’s called an ε-approximation—meaning the results are within a small, bounded error of the exact answer. It’s rather like having a compass that might be off by a few degrees but will still get you to your destination reliably4.
Performance That Actually Matters
The experimental results are rather striking. On the BEIR benchmark suite—a comprehensive evaluation framework for information retrieval systems—MUVERA achieved a 10% improvement in recall whilst reducing latency by 90% compared to existing methods89. To put this in perspective, it’s rather like making a sports car that’s both faster and more fuel-efficient than its predecessor.
MUVERA’s recall outperforms the single-vector heuristic, achieving better recall while retrieving significantly fewer candidate documents.
Perhaps more impressive is the memory efficiency. Using product quantization—a compression technique that reduces vector storage requirements—MUVERA achieved a 32× compression ratio whilst maintaining search quality910. This is crucial for web-scale deployment, where memory costs can be astronomical.
The Streaming Advantage
One particularly clever aspect of MUVERA is its data-oblivious nature. Unlike many machine learning systems that require extensive training on the specific dataset, MUVERA’s FDE construction doesn’t depend on knowing the distribution of the data beforehand4. This makes it ideal for streaming scenarios where new documents arrive continuously—rather like a library that can instantly categorise new books without knowing what’s already on the shelves1112.
Real-World Applications
The implications extend far beyond academic curiosity. Google’s search infrastructure processes approximately 63,000 queries per second, dealing with billions of documents13. MUVERA’s efficiency gains translate directly into reduced computational costs and faster response times. For YouTube’s recommendation system, which must process millions of user interactions in real-time, such improvements are particularly valuable1415.
The algorithm is also being deployed in Google’s other products. Search engines increasingly rely on semantic understanding rather than simple keyword matching16. MUVERA enables this sophisticated semantic search at the scale required by modern web applications.
The Broader Context
MUVERA arrives at a fascinating juncture in the evolution of information retrieval. Traditional keyword-based search is giving way to more sophisticated semantic approaches, but the computational demands have been prohibitive at web scale17. The algorithm represents a rather elegant solution to this dilemma—maintaining the sophistication of modern neural retrieval whilst preserving the efficiency of traditional methods.
The challenge of balancing accuracy and latency in vector search has been a persistent problem in the field. MUVERA’s approach of converting multi-vector problems into single-vector ones represents a fundamental shift in how we think about this trade-off.
The Quirks and Challenges
Of course, no algorithmic advancement is without its peculiarities—and here’s where we must be rather more critical. MUVERA’s performance depends heavily on the quality of the underlying multi-vector model. If ColBERT produces poor embeddings, MUVERA’s elegant compression won’t salvage the situation. It’s rather like having a superb audio compression system—it can only be as good as the original recording.
More troublingly, the algorithm’s reliance on Fixed Dimensional Encodings introduces what might be termed the “compression conundrum.”11 By condensing multiple vectors into a single representation, FDEs inherently involve some degree of information loss. This isn’t merely theoretical hand-waving—it’s a fundamental limitation that could affect the accuracy of initial candidate retrieval, particularly for highly specific or complex queries where fine-grained distinctions are crucial.
The algorithm’s reliance on Fixed Dimensional Encodings introduces what might be termed the ‘compression conundrum’… By condensing multiple vectors into a single representation, FDEs inherently involve some degree of information loss.
The parameter tuning requirements are also rather more demanding than Google’s research might suggest. The algorithm requires careful adjustment of various parameters, including the dimensionality of the FDEs and the number of candidates retrieved in the initial stage5. Getting these settings right requires considerable expertise and experimentation—hardly the “plug-and-play” solution one might hope for.
Perhaps most critically, MUVERA’s “data-oblivious” nature, whilst presented as an advantage, might also be seen as a limitation. The algorithm’s inability to adapt to specific data distributions could mean it performs suboptimally on certain types of content or query patterns4.
This one-size-fits-all approach, whilst convenient, may not be the most effective strategy for all use cases.
The Scalability Question
There’s also the rather thorny issue of scalability. Whilst MUVERA demonstrates impressive performance improvements on benchmark datasets, questions remain about its behaviour at truly massive scales. The compression ratios and efficiency gains observed in controlled experiments may not translate directly to the chaotic, ever-changing environment of the real web8.
The algorithm’s performance under extreme load conditions—such as viral content scenarios or rapid shifts in query patterns—remains largely untested. This isn’t merely an academic concern; it’s a practical limitation that could affect real-world deployment.
Looking Forward
What’s particularly intriguing about MUVERA is its potential for broader application. The principle of converting complex multi-dimensional problems into simpler single-dimensional ones could find applications in other domains—from recommendation systems to natural language processing.
The research also opens up interesting questions about the future of information retrieval. As language models become more sophisticated and multimodal search becomes common, the need for efficient multi-vector approaches will only increase.
The Indian Context
For India’s burgeoning tech ecosystem, MUVERA represents both an opportunity and a challenge. The country’s vast linguistic diversity and the growth of vernacular content create unique information retrieval challenges. MUVERA’s efficiency could enable more sophisticated search capabilities for Indian languages, but adapting the algorithm to handle the nuances of multilingual search remains an open research question.
The algorithm’s computational efficiency is particularly relevant for Indian companies operating under tighter resource constraints than their Silicon Valley counterparts. However, the technical expertise required for optimal implementation may pose barriers for smaller organisations.
The Verdict
MUVERA represents a rather elegant solution to a fundamental problem in modern information retrieval. By transforming multi-vector similarity search into single-vector MIPS, it achieves something approaching the holy grail of machine learning: better accuracy with lower computational cost. Whilst the algorithm may not generate headlines like ChatGPT or image generators, its impact on everyday search experiences will likely be far more profound.
Yet we must resist the temptation to herald MUVERA as a panacea. The algorithm’s limitations—from its dependence on underlying model quality to its potential for information loss through compression—remind us that even the most sophisticated engineering is subject to fundamental trade-offs.
The research demonstrates that sometimes the most significant advances come not from adding complexity, but from finding clever ways to reduce it. In an era where computational efficiency is increasingly important—both for environmental and economic reasons—MUVERA’s approach offers a blueprint for making sophisticated AI systems more practical and accessible.
Rather tellingly, the algorithm’s success lies not in its novelty, but in its synthesis of existing techniques in a particularly clever way. It’s a reminder that innovation often comes from seeing familiar problems from a fresh perspective—and that the most elegant solutions are often the simplest ones.
But perhaps the most important lesson from MUVERA is this: as we rush towards ever more sophisticated AI systems, we must remain mindful of the fundamental trade-offs between accuracy, efficiency, and complexity. The algorithm’s achievements are impressive, but they come with costs that we must acknowledge and understand.
In the end, MUVERA is neither a revolutionary breakthrough nor a mere incremental improvement—it’s something rather more interesting: a thoughtful engineering solution that advances the state of the art whilst respecting the constraints of the real world. And in our current moment of AI hyperbole, that sort of measured progress might be exactly what we need.
MUVERA’s arrival is not just another footnote in the long, often tedious history of Google algorithm updates. It’s a seismic shift—one with profound consequences for SEO and digital marketing, both in India and globally.
Semantic Search: The End of the Keyword Era
The most immediate casualty of MUVERA’s multi-vector, context-driven approach is the old regime of keyword stuffing and mechanical optimisation. Google’s new retrieval system is designed to understand meaning, not just match strings. This means that content which merely ticks keyword boxes will increasingly be outmanoeuvred by content that genuinely addresses user intent, context, and nuance1234.
What does this mean in practice?
- Topic Authority Trumps Keyword Density: Pages that offer comprehensive, well-structured coverage of a subject—answering the “why,” “how,” and “what next”—are far more likely to surface for complex queries. Shallow, repetitive content is on borrowed time123.
- Intent is Everything: MUVERA’s multi-vector magic allows Google to parse the scenario behind a query. For example, a search for “eco-friendly furniture for small balconies” will favour content that addresses the full context, not just those that mention the right nouns and adjectives34.
- Semantic Relationships Matter: Structured data, internal linking, and logical content architecture now help reinforce your site’s topical relevance and interconnectedness—key signals for MUVERA’s semantic retrieval124.
Technical SEO: No Longer Optional
MUVERA’s efficiency unlocks new technical demands. The algorithm can process complex semantic relationships at speed, but only if your site’s technical foundation is robust.
- Core Web Vitals are Critical: Fast loading times and smooth user experience are now prerequisites for ranking, not afterthoughts. Sites that lag on metrics like Largest Contentful Paint will find themselves filtered out before semantic analysis even begins3.
- Structured Data and Content Hierarchy: Schema markup and clear content organisation help Google’s algorithms “see” the relationships between entities, topics, and answers—boosting your chances of being selected for featured snippets and AI-driven summaries124.
Digital Marketing Strategy: Adapt or Fade
For digital marketers, MUVERA’s impact is both exhilarating and daunting.
- Content Must Serve Users, Not Algorithms: The focus shifts to creating genuinely helpful, scenario-driven, and authoritative content. This is good news for brands that invest in quality, but bad news for those still chasing shortcuts.
- Voice and Multimodal Search: As MUVERA’s principles are extended to images, video, and voice, marketers must think beyond text. Content should be optimised for natural language queries and structured to answer questions in formats suitable for voice assistants and AI-powered search24.
- Personalisation and Recommendation: MUVERA’s real-time, scalable retrieval powers more personalised content delivery and recommendation systems. Marketers can expect Google to surface a wider variety of perspectives and content types, making brand visibility more competitive—but also more meritocratic124.
The Critical Perspective: Not All Sunshine and Rainbows
Let’s not gush uncritically.
- Complexity Rises, Accessibility Falls: The sophistication of MUVERA’s retrieval means that SEO is now a technical and editorial discipline. Small publishers and non-technical creators may find it harder to compete without access to advanced tools and expertise3.
- Opaque Ranking Factors: As semantic retrieval deepens, the “why” behind rankings becomes even less transparent. This may frustrate those seeking clear, actionable guidance.
- Content Quality Arms Race: As everyone pivots to “comprehensive, authoritative” content, the bar for standing out rises. The risk: a glut of long, but ultimately undifferentiated, content.
In the Indian Context
MUVERA’s promise is tantalising for India’s digital ecosystem, with its linguistic diversity and explosion of vernacular content. Yet, the challenge will be in ensuring that semantic models are trained on, and sensitive to, the nuances of Indian languages and contexts—a project that remains unfinished.
In Summary
MUVERA is a technical marvel and a challenge to complacency. For SEO and digital marketing, it signals a future where meaning, intent, and user experience are the currency of visibility. Those who adapt—by investing in quality, structure, and technical excellence—will thrive. Those who cling to the ghosts of keyword past may find themselves left behind1234.
References
1: Kiran Voleti – Google’s MUVERA Algorithm
: Google Research – MUVERA Blog Post
: Pinecone – Cascading Retrieval with Multi-Vector Representations
2: Qdrant – FastEmbed ColBERT Documentation
3: LinkedIn – Exploring Chamfer Distance
4: ArXiv – MUVERA Paper
5: ArXiv HTML – MUVERA Paper
6: Stanford – Tree Embedding Notes
7: MIT – Algorithm Notes
8: OpenReview – MUVERA Forum
9: ArXiv – BEIR Benchmark
10: Weaviate – Product Quantization
11: AlgoCademy – Streaming Data Algorithms
12: Number Analytics – Streaming Algorithms
13: Focal – AI Search Latency Metrics
14: Data Flair – YouTube Recommendation System
15: Google Research – YouTube Recommendations
: FinProv – Semantic Search
16: MeiliSearch – Semantic Search
17: HackerNoon – Web-Scale Information Retrieval
: Amazon Science – Web-Scale Semantic Search
: Milvus – Balancing Accuracy and Latency
: Coveo – Information Retrieval Issues
: Milvus – Open Problems in Information Retrieval
Add to follow-up
- https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/attachments/10660488/c5c30aa3-8411-442b-9c20-61a5f987759f/The-Curious-Case-of-MUVERA.docx
- https://kiranvoleti.com/googles-muvera-algorithm
- https://topmostads.com/muvera-multi-vector-retrieval-algorithm-googles-deep-dive/
- https://research.google/blog/muvera-making-multi-vector-retrieval-as-fast-as-single-vector-search/
- https://proceedings.neurips.cc/paper_files/paper/2024/file/b71cfefae46909178603b5bc6c11d3ae-Paper-Conference.pdf
- https://www.searchenginejournal.com/googles-new-muvera-algorithm-improves-search/550070/
- https://www.themoonlight.io/en/review/mint-multi-vector-search-index-tuning
- https://openreview.net/forum?id=X3ydKRcQr6
- https://www.linkedin.com/pulse/googles-new-muvera-algorithm-why-seos-content-creators-arun-sharma-gggvc
- https://thesai.org/Downloads/Volume15No10/Paper_7-Data_Encoding_with_Generative_AI.pdf
- https://weaviate.io/blog/muvera
- https://www.fixtrading.org/standards/sbe-online/
- https://arxiv.org/html/2405.19504v1
- https://www.dhiwise.com/post/positional-encoding-guide-for-transformers-in-ai
- https://www.pinecone.io/blog/cascading-retrieval-with-multi-vector-representations/
- https://arxiv.org/abs/2304.01982
- https://www.linkedin.com/pulse/multi-vector-revolution-how-muvera-transforming-retrieval-geraci-fv2sc